Appendix B: Trending Regression Analysis
Objective
The objective of this analysis is to assess whether damage counts are changing significantly[1] over time in the United States after accounting for several potential driving factors (e.g., economic growth).
Method
As in past years, regression analysis was used to relate damage counts by month and state to a set of explanatory variables including factors related to the economy, demographics, dig activity, etc. However, for the current analysis focused on trends over time year variables were added to account for changes over the different years included in the analysis (2020 to 2022).
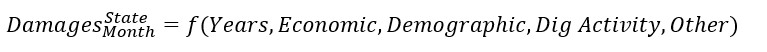
Given that the damage data are structured as count data, Poisson and negative binomial count models were used for the analysis. Both models are typically used to estimate count data, but the negative binomial model relaxes a key assumption of the Poisson model (via an overdispersion parameter). Non-panel models were run with robust standard errors clustered on the geographic unit (state) which account for the panel nature of the data.
For this year’s analysis, we also took a step back and ran count models at the level of the country (Equation 2). This overcomes certain limitations of models at the state level, such as noise introduced by variation in damage counts resulting from how the data was assembled (e.g., the subset of consistent companies may not properly represent all states leading to variation across states not representative of actual damage activity). However, other limitations present themselves at this scale including that so few observations may increase multicollinearity and results may still be skewed towards states which are better represented in the assembled dataset. Furthermore, data on certain variables is only collected at annual timescales meaning that these variables cannot be included in the regression analysis due to multicollinearity (e.g., One Call transmissions or PHMSA data).
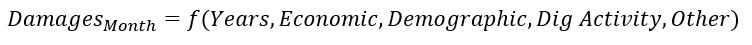
This relationship was modeled following procedures similar to those used for the state level analysis. Poisson and negative binomial count models were used both estimated with robust standard errors.
The coefficients of interest for the trend analyses are those on variables representing the years in Equations 1 or 2. If these coefficients are significantly different from zero after accounting for the other factors in this equation, then damage counts are changing over time for reasons other than the factors incorporated into the model. Before running the regression models, multicollinearity between variables was assessed using variance inflation factors (VIF). Since multicollinearity can influence how regression coefficients for certain variables are interpreted, highly collinear variables were iteratively removed according to their VIF using a VIF threshold of 5. This resulted in the primary models having a reduced set of variables with limited collinearity and regression analyses were conducted on this reduced set as well as the total set of variables.
[1] In statistics, “significant” means you can feel confident the effect is real rather than random, i.e., that you didn’t just get lucky (or unlucky) in choosing the sample.